
BUAA-OO-2024-Unit3
前言——唉,JML
本单元的主题为基于规格的层次化设计,相较于前两个单元的问题抽象与分解、并发程序设计,这单元的难度算是降低了不少吧——所有的方法与接口都由规格给出,只需要根据约定、将功能一一实现即可(暂不考虑程序性能的前提下)。
在我看来,其实不用太纠结于这里有什么毛病,那里有什么毛病,虽然有时看起来确实很滑稽(比如由于其形式化的描述,费了老半天劲写出来的东西自然语言一句话就讲明白了),最主要的一点还是去感受契约式设计的魅力(见仁见智把)。
规格设计者(架构师)基于规格和需要实现的业务,定义一个类所需管理的数据及其需要满足的约束和实现不同作用的方法;而程序员则遵循对每个对象和方法的要求,只需聚焦于具体方法的实现。当然在保证没有二义性的前提下,大篇大篇的数理逻辑表述确实又臭又长(所以这学期助教们对用于教学的JML的简化工作确实挺好的)。不过这样的形式化的表述,在另一方面确实有利于对代码进行各种验证和测试:
所以在实际项目开发过程中,感觉自然语言和规格语言并不应该是相斥的,不是只能有一个存在。(教学中只给JML并要求能看懂,倒也能理解)
还有一点要说的是,描述的规格是我们希望我们管理的数据会产生什么样的行为/变化,在实际实现的过程中我们不应逐字逐句翻译(一些时候无法满足性能要求甚至难以翻译),而应采用合适的算法、数据结构,以及将方法的逻辑拆解成小的功能模块;另外,如果我们要写出一个已实现的方法对应的(虽然感觉这个行为很难评),也不能一句一句翻译,比如这个方法用了某种算法,那使用的算法的细节并不是或者说规格关心的,关注的是数据或者对象状态的变化。比如下面这个求解字符串莱文斯坦距离的例子:
1 | public class Levenshtein { |
关于测试
黑盒测试与白盒测试
黑盒测试:
- 基于代码的规格说明和功能需求进行的测试
- 作为测试人员,我们不需要了解代码的内部结构或实现细节,而是将其视为一个黑盒子,只关注其输入和输出之间的关系,检验对错(设置各种
Corner Cases以及压力测试等) - 这类测试主要是用于验证代码的行为是否符合预期
- 这单元我们根据规格进行的测试就属于黑盒测试
白盒测试:
- 基于代码的内部结构和实现细节进行的测试
- 我们需要了代码内部逻辑和使用的算法,并针对地设计测试用例
- 通常需要关注代码覆盖率、分支覆盖率等各种覆盖率,比如上学期要求的
其他多种测试
- 单元测试
- 单元测试是针对软件中的最小可测试单元进行的测试,通常是代码中的一个函数、方法或类。
- 单元测试的目标是验证每个单元的功能是否符合预期,以确保代码的每个部分都能正常工作。
- 例如,本单元对社交网络的单元测试可以包括对各种增加/删除元素、查询、发送信息等功能进行测试,每个功能被视为一个单元。
- 功能测试
- 功能测试是测试软件的功能是否按照规格说明和用户需求的预期工作。
- 在功能测试中,我们需要模拟用户操作,验证软件的各项功能是否符合预期,包括输入验证、功能流程、界面交互等。
- 例如,对于一个电子商务网站,功能测试可以包括用户注册、浏览商品、下订单、支付等功能的测试。
- 集成测试
- 集成测试是测试软件中不同模块或组件之间的交互和集成是否正常。
- 在集成测试中,我们需要将各个模块组合起来,并测试它们之间的接口和交互是否符合设计要求。
- 例如,对于一个社交网络应用,集成测试可以包括用户登录、发布动态、评论、点赞等功能的整体测试。
- 压力测试
- 压力测试是测试软件在负载过高或资源不足的情况下是否能够正常工作。
- 在压力测试中,我们可以模拟大量用户同时访问系统或者增加系统负载,以测试软件的性能、稳定性和可靠性。
- 例如,对于一个在线游戏服务器,压力测试可以模拟大量玩家同时在线、进行游戏,以测试服务器是否能够承受住这样的负载。或者对于我们
喜闻乐见的互测来说,生成各种极限数据。
- 回归测试
- 回归测试是在软件发生变更后重新执行之前的测试用例,以确保变更不会对软件的其他部分造成影响。
- 在回归测试中,我们需要针对变更的部分以及相关联的功能重新执行测试用例,并验证软件的整体功能是否受到影响。
- 例如,当我们每次修复bug或者进行迭代后,也要使用之前已经通过的数据对代码进行测试,以确保bug修复没有引入新的问题😃
总之,这些测试类型在软件或项目开发过程中起着不同的作用,我们可以通过综合运用有效地提高软件的质量、可靠性、可维护性。
数据构造策略
除了使用大佬们提供的评测机,我构造数据的主要策略是,针对一些需要优化的指令进行压力测试。
比如第二次互测时,对于指令queryTagValueSum,我构造数据的具体策略如下:
load_network(100人)at 1 1(给加上Tag)- 增加个人并与连边,然后连同前面的个人,一块加入上述Tag中
- 最后剩下的操作全部执行
qtvs
简单计算可知,取约时压力最大(针对双重循环来说)。
架构设计
本单元的主要任务是实现一个简单的社交网络。
具体的UML类图如下
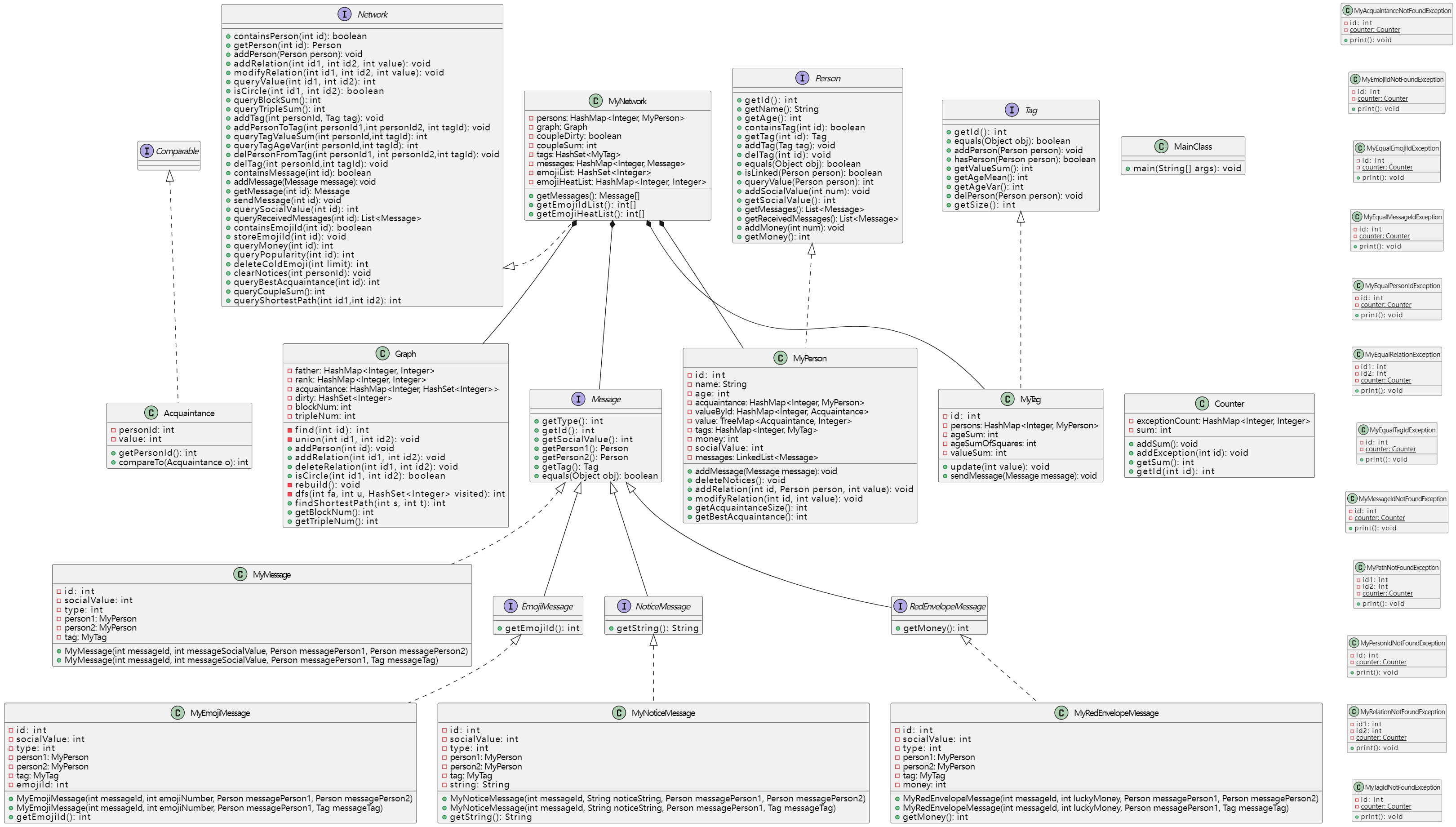
虽然基本上规格都由给出了,但它只是定义了方法或者接口的外部可感知行为及其约束,以及需要管理的数据所要满足的要求,实际编写代码时,我们需要灵活使用不同算法和数据结构,才能在保证性能的同时达成想要的效果。
在本单元作业实现中,我新建了Graph类,使用邻接表存储信息,将绝大部分维护信息的工作从Network类中分出来,Network只负责实现各种业务的接口。
其他的部分如Tag、Person、Message和异常类则由规定好了,总体结构没有什么特别的地方。
时间复杂度分析
本单元要求维护一张关系图(初始为空),并支持修改和查询操作(指令数)。为了在时限内通过所有数据,我们需要保证每种操作的时间复杂度最多为,在保证正确性的基础上再尝试进行复杂度优化或常数优化。
首先是最基本的add relation和modify relation,其实可以实现,但是为了避免queryTripleSum、queryTagValueSum等操作的多重循环,需要在修改关系的时候对相关的信息进行维护,这样上述的查询操作就可以完成。
1 | //Graph.addRelation() |
对于TagValueSum的维护,与其费劲心思在Person类中维护信息,我选择了比较简单的实现,直接在Network中记录所有出现的Tag,修改所有满足条件的Tag即可。
1 | //Tag.addPerson(), 删人同理 |
对于queryTagAgeVar,计算方差原本是的,不过可以在addPersonToTag、delPersonFromTag时维护,然后就可以做到查询方差。
对于queryShortestPath,实际就是01最短路,直接即可(也可以双向,减小常数),复杂度(为边数小于指令数)
1 | public int findShortestPath(int s, int t) { |
对于queryBestAcquaintance,其实查询也没问题,不过由于queryCoupleSum的存在,基本上要求必须在常数时间内实现qba。
当然我们还是可以再加人/删人的时候维护最大值,不过我选择了用去存acquaintance相关信息,这样就可以降低复杂度至。
由于只能以键值进行排序,研究了一阵子不得以我只能以一种很不优雅的方式自定义了比较器😕
1 | //Person.java |
其他指令基本上根据来就好,除了维护整张图关系的并查集,基本没有使用算法和数据结构进行优化的必要了。
并查集的延迟重建
本来我们可以使用路径压缩+启发式合并的并查集,做到每个关系修改和查询(isCircle)操作的平均时间为(可以认为是很小的常数),同时queryBlockSum也可以维护和查询。
不过有了modifyRelation删边操作,我们不得不在某些时候对并查集进行重建。
-
如果是每次判断需要删边时无脑全部重建,则很大可能会被卡烂掉(常数+评测机波动)
-
每次删边时部分重建,常数小了很多,不过很多时候不太必要(因为只有查询的时候才需要准确的
BlockSum和isCircle)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//Graph.deleteRelation()
HashSet<Integer> visited = new Hashset<>();
father.put(id1, id1);
dfs(id1, id1, visited);
rank.put(id1, visited.size());
if (!visited.contains(id2)) {
father.put(id2, id2);
visited.clear();
dfs(id2, id2, visited);
rank.put(id2, visited.size());
}
//dfs
private dfs(int fa, int u, Hashset<Integer> visited) {
visited.add(u);
for (int v : acquaintance.get(u)) {
if (!visited.contains(v)) {
father.put(v, fa);
rank.put(v, 1);
dfs(fa, v, visited);
}
}
} -
或者删边时设置脏位,需要查询时才重建并查集。不过这样的话,当修改和查询指令轮流到来时,这个方法会和
1一样拉(因为会无脑全部重建)
结合以上思路我们可以设计一种带有精确脏位的并查集(思路来自讨论区jhz同学的分享)
具体来说,我们可以将原来标记整个图的脏位扩展为对每个联通块进行脏位标记,设置dirty为所有被删边操作污染的父节点
1 | private final HashSet<Integer> dirty; |
重建的步骤为
- 若
dirty不为空,则所有的父节点在dirty中的点是我们需要重建的点 - 从需要重建的点的集合中开始,重建这部分并查集
1 | private void rebuild() { |
这是对于查询操作,queryBlockSum我们需要调用rebuild。
而对于isCircle,需要分以下几种情况讨论:
- 若
!dirty.contains(f1) && !dirty.contains(f2),则这两个联通块都未被污染,正常判断即可 - 若
dirty.contains(f1) && dirty.contains(f2),则此时对我们来说这两个联通块的状态是“薛定谔的”,需要重建 - 而若两个父亲只有一个脏位被标记,这是我们立即得出被查询的两个点是不联通的(因为显然这两个点父节点不一样)
剩下的就是正常的并查集的相关操作,不过最后还有一点需要注意血泪教训:
就是并查集合并的时候,需要优先将没有脏位的父节点合并到有脏位的父节点,否则这个联通块的脏位信息是不准确的
1 | private void union(int id1, int id2) { |
由于重建操作只在需要的时候进行,并且我们精确了重建的点的范围,无论对于什么数据,这种方法相较于前面几种都是只优不劣的。
容器类的选择和轮子的使用
由于本单元维护的是一个社交网络,每个对象的是独一无二的,且取值范围是,所以我们可以很自然地想到用使用HashMap,建立到各种属性/对象的映射。
而对于其他一些不需要这样的映射的对象的集合,则基本来说HashSet是较优的选择(因为对象不重复且可以使用contains)。
然后对于getReceivedMessages,要求返回前个Message,所以不能内部无序的HashMap或HashSet。经过查阅资料和参考讨论区czx同学的思路分享,最终选择了基于链表的LinkedList来存储Messages。
具体操作为:添加Message时使用addFirst方法,删除时使用removeIf方法。
1 | //Person.java |
对于删除上述容器中的特定元素操作,一般而言,我们都会采用迭代器的形式去遍历
1 | Iterator<E> it = collection.iterator(); |
但其实Collection接口定义了方法removeIf,我们需要实现的删除操作正可以用这个现成的方法来实现,而且看起来十分优雅。下面是removeIf的相关用法。
1 | boolean removeIf(Predicate<? super E> filter); |
其中,Predicate是函数式接口,用于表示一个断言,该函数接受一个参数并返回布尔值。在 removeIf 方法中,传入一个 Predicate 类型的参数,表示要移除的元素需要满足的条件。若删除成功则返回真。
-
可以使用表达式(允许把函数作为一个方法的参数)定义过滤条件
1
2
3
4
5
6
7
8
9
10
11
12
13
14/*
(parameters) -> expression
或
(parameters) -> { statement; }
*/
//比如删除所有的NoticeMessage
messages.removeIf(message -> message instanceof MyNoticeMessage);
//删除emojiList中emojiHeatList不存在的key
emojiList.removeIf(emoji -> !emojiHeatList.containsKey(emoji));
//删除emojiList中emojiHeatList存在的key(方法引用)
emojiList.removeIf(emojiHeatList::containsKey); -
自定义一个实现
Predicate接口的类来定义过滤条件1
2
3
4
5
6
7Collection<E> collection = new ArrayList();
collection.removeIf(new Predicate<E>() {
public boolean test(...) {
//...
}
});
性能与bug修复
本单元一个最大的优化就是实现了并查集的延迟重建功能。
其实hw9的时候我想着因为有删边,不管怎样处理都要,所以直接无脑重建(想的是反正最多是而且时限),但是由于load_network指令的存在,第一次作业数据范围给的就显得有点大了(虽然后面改小了,虽然强测掉的点打赢复活赛了)。所以后面两次作业改成了延迟重建的并查集。
然后就是hw10强测和互测的bug,其实挺不应该的,queryTagValueSum直接写的双重循环计算。但是我这么做也是有理由的,你听我慢慢狡辩。首先是当时维护的过程出了一点麻烦,一直没搞清楚哪里出了问题,并且由于中测也只有两次机会了;然后翻了翻hw9打赢复活赛的点,发现只给了一千条左右的指令,想着课程组还挺良心的嘛,数据确实有梯度😃。
总之最后还是懒了,没改原来的双重循环,结果强测(一万条指令)和互测人直接被卡晕掉了。这波被课程组狠狠背刺了。
hw11互测出了bug,就是上文提到的十分隐蔽的关于延迟重建的并查集的合并细节,收回伏笔了属于是。
对于规格与实现分离的理解,其实已经体现在架构设计中了。
设计一些规格之外的方法,辅助业务代码的实现;而这其中又可以灵活采用合适的算法、数据结构等。
总的来说,这单元做得不是很好吧,本来轻松可以避免的bug没有去做,感觉经历了上个单元电梯的拷打、两次作业费尽心思写影子电梯但最终都没有做到完美,和这单元又碰上,整个人有点懒了。
但是不管怎么说,课程要进入最后一个单元了,能力(指狼狈地修复bug时)还是一如既往地在线。
JUnit测试
上学期的时候已经品尝过了,当时感觉是真的鸡肋,也不好写。
这单元学了和怎么对规格进行测试,(虽然可能是装模作样地在测试规格)感觉又还行了。
主要还是模仿实验课上的代码,使用Parameters生成数据搭建测试框架,如:
1 |
|
心得体会
这单元的学习,算是让我了解到了“契约式编程”这一思想吧,其实这单元照着规格实现代码的时候,我还是感觉挺受用的(雾,然后还是挺期待以后大项目的实践中能够真正接触到它。
然后其他的体会,前文写了很多,这里就不再说了。
最后关于,其实我没什么意见,助教们写的推送给我帮助很大,感谢十分用心的助教们。


