高级搜索树
伸展树
- 局部性:刚被访问过的数据,极有可能很快地再次被访问
- BST 的局部性
- 时间:刚被访问过的节点,极有可能很快地再次被访问
- 空间:下一将要访问的节点,极有可能就在刚被访问过节点的附近
- 对于 AVL 的连续 m≫n 次查找,共需 O(mlogn)
- 利用局部性加速:BST 的节点一旦被访问,随即调整到树根
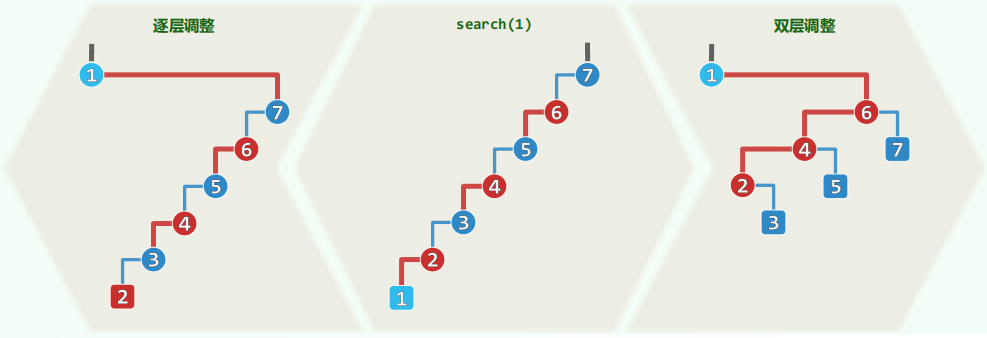
单层伸展
- 节点 v 一旦被访问,随即被推送至根
- 旋转次数呈周期性的算术级数(周期访问所有节点)
- 每一周期结构会复原,累计 Ω(n2) ,分摊 Ω(n)
双层伸展
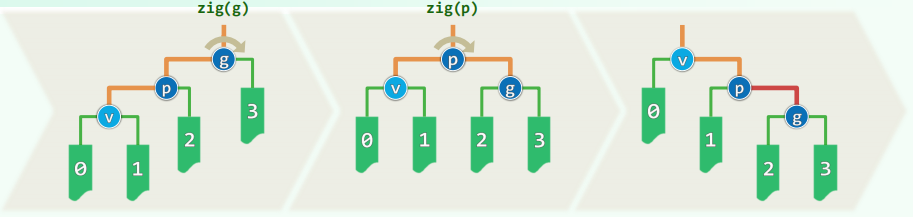
- 反复考察祖孙三代
g = parent(p), p = parent(v), v- 根据他们的相对位置,经 两次旋转,使
v 上升两层,成为子树根
zig-zag 操作本身就是平衡的,效果很好- 对于
zig-zig,先 p 后 g 只会拉长和移动访问路径,无法改善树的整体结构;而先 g 后 p 则能够“折叠”和“打散”访问路径
- zig 和 zag 不同组合,共计 4 种
- 节点访问之后,对应路径的长度随即 折半
- 最坏情况显然 O(n) ,但最坏情况不致持续发生
- 分摊仅需 O(logn)
算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| template<typename T> BinNodeposi<T> Splay<T>::splay(BinNodePosi<T> v) {
BinNodePosi<T> p, q;
while ((p = v->parent) && (g = p->parent)) {
BinNodePosi<T> gg = g->parent;
switch ((IsLChild(p) << 1) | IsLChild(v)) {
case 0b00: ;
case 0b01: ;
case 0b10: ;
default: ;
}
if (!gg) v->parent = NULL;
else (g == gg->lc) ? gg->attachLc(v) : gg->attachRc(v);
g->updateHeight(); p->updateHeight(); v->updateHeight();
}
if (p = v->parent) {
if (IsLChild(v)) {
p->attachLc(v->rc);
v->attachRc(p);
} else {
p->attachRc(v->lc);
v->attachLc(p);
}
p->updateHeight(); v->updateHeight();
}
v->parent = NULL; return v;
}
|
查找
- 与常规
BST::search() 不同,很可能会改变树的拓扑结构, 不再属于静态操作
1
2
3
4
5
| template<typename T> BinNodePosi<T>& Splay<T>::search(const T &e) {
BinNodePosi<T> p = BST<T>::search(e);
_root = p ? splay(p) : _hot ? splay(_hot) : NULL;
return _root;
}
|
插入
Splay::search() 查找失败后,_hot 即为根
1
2
3
4
5
6
7
8
9
10
11
12
13
| template<typename T> BinNodePosi<T> Splay<T>::insert(T const &e) {
if (_root) { _size = 1; return _root = new BinNode<T>(e); }
BinNodePosi<T> t = search(e);
if (t->data == e) return t;
if (t->data < e) {
_root = new BinNode<T>(e, NULL, t, t->rc);
t->rc = NULL;
} else {
_root = new BinNode<T>(e, NULL, t->lc, t);
t->lc = NULL;
}
_size++; t->updateHeightAbove(); return _root;
}
|
删除
- 同插入,
search() 后可直接在树根附近摘除节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| template<typename T> bool Splay<T>::remove(T const &e) {
if (!root || e != search(e)->data) return false;
BinNodePosi<T> L = _root->lc, R = _root->rc;
delete _root;
if (!R) {
if (L) L->parent = NULL;
_root = L;
} else {
_root = R; R->parent = NULL;
search(e);
_root->attachLc(L);
}
_size--; if (_root) _root->updateHeight();
return true;
}
|
总结
- 无需记录高度或平衡因子,编程实现简单,分摊复杂度 O(logn)
- 局部性强,缓存命中率极高时(k≪n≪m)(k 为访问范围)
- 效率甚至可以更高,自适应的 O(logk)
- 任何 连续 的 m 次查找,仅需 O(mlogk+nlogn)
- 若 反复地顺序 访问任意子集,分摊成本仅为常数
- 不能杜绝 单次最坏 情况,不适用于对效率敏感的场合
分摊分析
势能
-
任何一棵伸展树在任何时刻,都可假想地视作具有势能
- Φ(S)=log(∏v∈Ssize(v))=∑v∈Slog(size(v))=∑v∈Srank(v)=∑v∈SlogV
-
越平衡/倾侧的树,势能越小/大
-
单链
Φ(S)=logn!=O(nlogn)
-
满树
Φ(S)=logd=0∏h(2h−d+1−1)2d≤logd=0∏k2(h−d+1)⋅2d=d=0∑h(h−d+1)⋅2d=(h+1)⋅(2h+1−1)−[(h−1)⋅2h+1+2]=2h+2−h−3=O(n)
总体关系推导
- 考察对伸展树 S 的 m≫n 次连续访问(不妨仅考察
search() )
- 记 A(k)=T(k)+ΔΦ(k) ,其中
- T(k) :第 k 次操作的实际时间复杂度
- ΔΦ(k)=Φafter−Φbefore :第 k 次操作后势能函数的变化
- 则有 T=∑k=1mT(k)=∑k=1m(A(k)−ΔΦ(k))=A−ΔΦ
- 其中 ∣ΔΦ∣≤O(nlogn)
- 故 T=A±O(nlogn)
- T(k) 的变化幅度可能很大,但可以证明 A(k) 都不致超过节点 v 的势能变化量
- A(k)=O(rank(k)(v)−rank(k−1)(v))=O(logn)
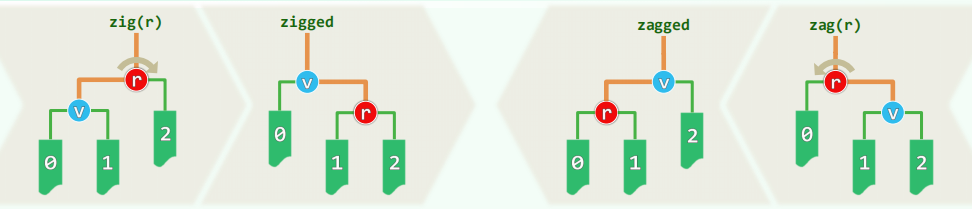
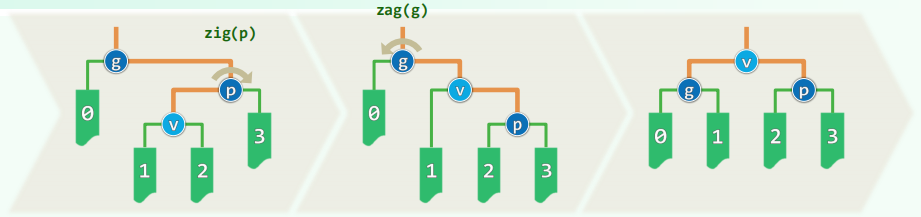
伸展操作分析
-
反向双旋(zig-zag / zag-zig),(logGi+logPi)/2≤log((Gi+Pi)/2)<log(Vi/2)
Ai(k)=Ti(k)+ΔΦi(k)=2+Δranki(g)+Δranki(p)+Δranki(v)=2+[ranki(g)−ranki−1(g)]+[ranki(p)−ranki−1(p)]+[ranki(v)−ranki−1(v)]<2+ranki(g)+ranki(p)−2⋅ranki−1(v)<2+2⋅ranki(v)−2−2⋅ranki−1(v)=2⋅(ranki(v)−ranki−1(v))
-
同向双旋(zig-zig / zag-zag),(logGi+logVi−1)/2≤log((Gi+Vi−1)/2)<log(Vi/2)
Ai(k)=Ti(k)+ΔΦi(k)=2+Δranki(g)+Δranki(p)+Δranki(v)=2+[ranki(g)−ranki−1(g)]+[ranki(p)−ranki−1(p)]+[ranki(v)−ranki−1(v)]<2+ranki(g)+ranki(p)−2⋅ranki−1(v)<2+ranki(g)+ranki(v)−2⋅ranki−1(v)<2+2⋅ranki(v)−ranki−1(v)−2+ranki(v)−2⋅ranki−1(v)=3⋅(ranki(v)−ranki−1(v))
-
单次伸展总复杂度为
A(k)=i∑Ai(k)≤3⋅i∑(ranki(v)−ranki−1(v))=3⋅(rank(root)−rank(v))≤3⋅logn=O(logn)
B-树
-
分级存储:利用数据访问的局部性
- 常用的数据,复制到更高层、更小的存储器中
- 找不到,才向更低层、更大的存储器索取
-
缓存的体现: 就地 循环位移的倒置版本
1
2
3
4
5
| void shift(int *A, int n, int k) {
reverse(A, k);
reverse(A + k, n - k);
reverse(A, n);
}
|
结构
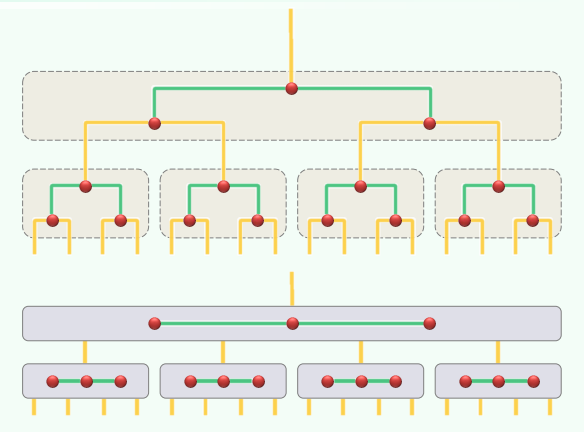
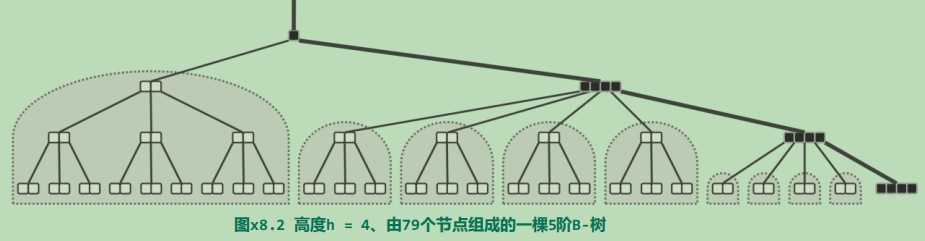
外部节点+叶子
- m 阶 B-树,即为 m 路完全平衡搜索树(m≥3)
- 外部节点的深度 统一相等,并以此深度作为树高 h
- 外部节点可看作 “可被插入的空隙”
- 叶节点的深度统一相等(h−1)
内部节点
- 各含有 n≤m−1 个关键码
- 各有 n+1≤m 个分支
- 反过来,分支数也不能太少
- 树根:2≤n+1
- 其余:⌈m/2⌉≤n+1≤m
- 故亦称作 (⌈m/2⌉,m)-树
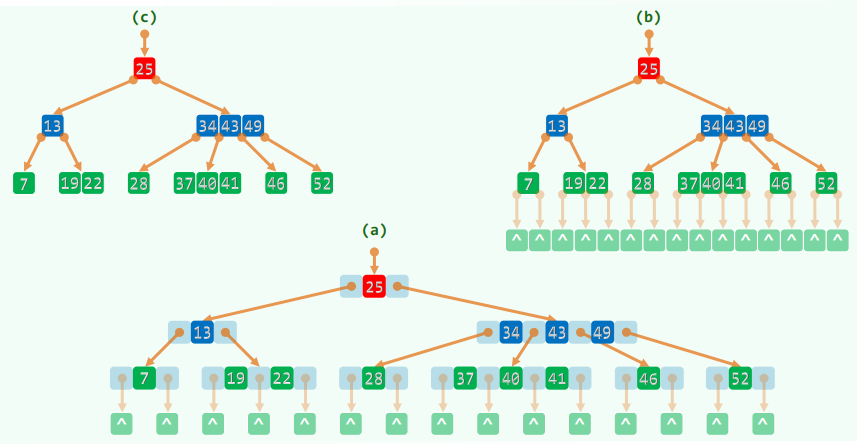
查找
算法
- 从(常驻 RAM 的)根节点开始
- 只要当前节点不是外部节点
- 在当前节点中顺序查找(RAM 内部)
- 若找到目标关键码,则返回查找成功
- 否则,沿引用找到孩子节点,将其 读入内存
- 返回查找失败
实现
1
2
3
4
5
6
7
8
9
10
| template<typename T> BTNodePosi<T> BTree<T>::search(T const &e) {
_hot = NULL;
for (BTNodePosi<T> v = _root; v; ) {
Rank r = v->key.search(e);
if (r != -1 && (e == v->key[r])) return v;
_hot = v; v = v->child[r + 1];
}
return NULL;
}
|
性能
- 忽略内存中的查找,运行时间主要取决于 I/O 次数
- 在每一深度至多一次 I/O,故运行时间为 O(logn)
- logm(N+1)≤h≤1+⌊log⌈m/2⌉2N+1⌋
- 树最高的情况
- 对于内部节点,nk≥2×⌈m/2⌉k−1,∀k>0
- 考察外部节点所在高度 h,N+1=nh≥2×⌈m/2⌉h−1
- h≤1+⌊log⌈m/2⌉2N+1⌋=O(logmN)
插入
1
2
3
4
5
6
7
8
9
| template<typename T> bool BTree<T>::insert(const T &e) {
BTNodePosi<T> v = search(e);
if (v) return false;
Rank r = _hot->key.search(e);
_hot->key.insert(r + 1, e);
_hot->child.insert(r + 2, NULL);
_size++; solveOverflow(_hot);
return true;
}
|
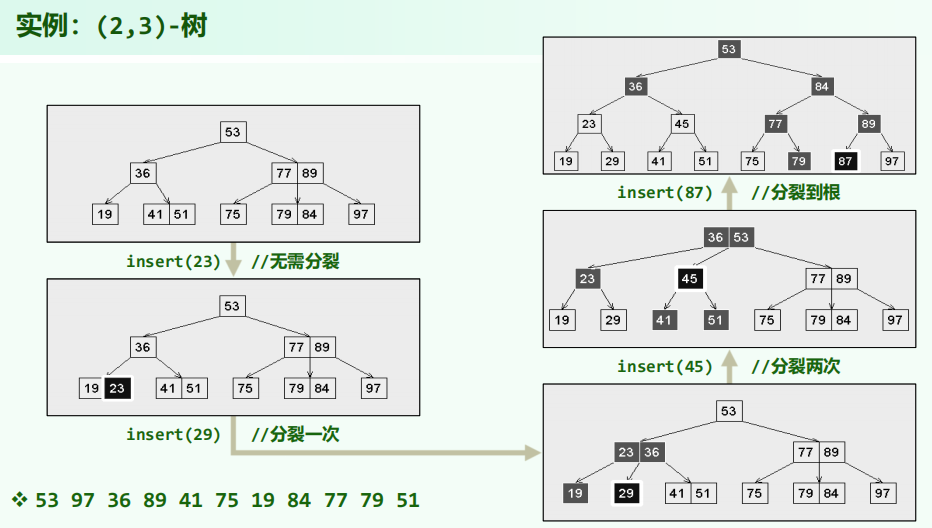
上溢修复
- 设上溢节点中的关键码依次为 {k0,k1,…,km−1}
- 取中位数 s=⌊m/2⌋ ,划分为 {k0,…,ks−1} 、{ks} 、{ks+1,…,km−1}
- 关键码分裂,ks 上升成为父节点的孩子,其余两部分成为它的左、右孩子
- 此时左、右孩子的关键码数目,均满足 m 阶 B-树条件
- 若父节点本已饱和,则继续上溢
- 最坏情况 上溢持续 向上传播到根
- 此时可令最后被提升的关键码自成节点,作为新的根
- B-树因此增高
- 总体执行时间正比于分裂次数,O(h)
- 上溢也可采用旋转来修复
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| template<typename T> void BTree<T>::solveOverflow(BTNodePosi<T> v) {
while (_m <= v->key.size()) {
Rank s = _m / 2;
BTNodePosi<T> u = new BTNode<T>();
for (Rank j = 0; j < _m - s - 1; j++) {
u->child.insert(j, v->child.remove(s + 1));
u->key.insert(j, v->key.remove(s + 1));
}
u->child.insert[_m - s - 1] = v->child.remove(s + 1);
if (u->child[0]) {
for (Rank j = 0; j < _m - s; j++)
u->child[j]->parent = u;
}
BTNodePosi<T> p = v->parent;
if (!p) {
_root = p = new BTNode<T>();
p->child[0] = v, v->parent = p;
}
Rank r = 1 + p->key.search(v->key[0]);
p->key.insert(r, v->key.remove(s));
p->child.insert(r + 1, u); u->parent = p;
v = p;
}
}
|
一棵存有 N 个关键码的 m 阶 B-树插入特定关键码后,引发 Θ(logmN) 次分裂的情况:
- 全树总规模为 N^=⌈m/2⌉h−1+(m−1)⋅(⌈m/2⌉h−2+⌈m/2⌉h−3+⋯+⌈m/2⌉0)
- 对应高度可取为 h=1+log⌈m/2⌉((N^⋅(⌈m/2⌉−1)+m−1)/(m+⌈m/2⌉−2))=Θ(log⌈m/2⌉N^)=Θ(logmN^)
- 对于给定的 N,可由代入上式计算出 h 进而估算出 N^≤N(多余的关键码散布至其他子树中)
图示某一黑关键码和对应白关键码构成的 高度 为 k 的子树规模为 ⌈m/2⌉k
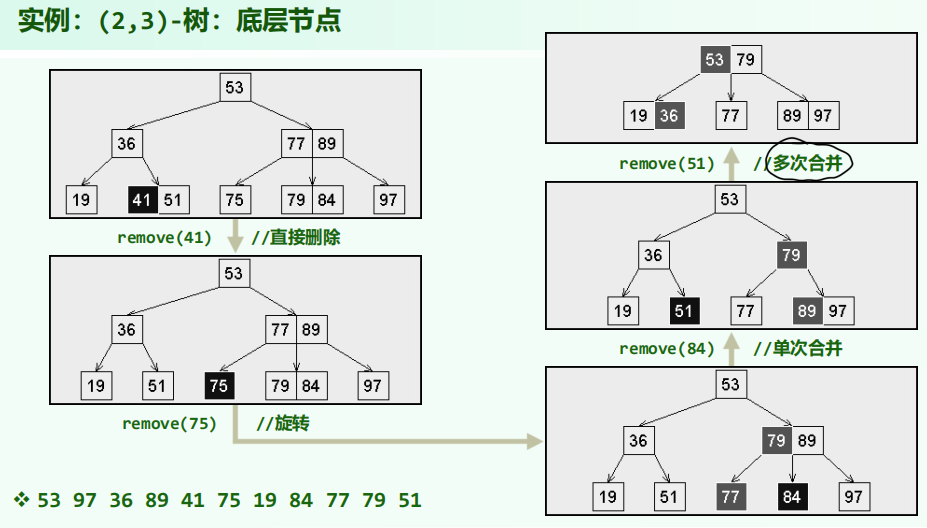
删除
- 若被删除元素非叶子,则先通过旋转 腾挪(与后继交换),使其位于最底层
1
2
3
4
5
6
7
8
9
10
11
12
13
| template<typename T> bool BTree<T>::remove(const T &e) {
BTNodePosi<T> v = search(e);
if (!v) return false;
Rank r = v->key.search(e);
if (v->child[0]) {
BTNodePosi<T> u = v->child[r + 1];
while (u->child[0]) u = u->child[0];
v->key[r] = u->key[0]; v = u, r = 0;
}
v->key.remove(r); v->child.remove(r + 1);
_size--; solveUnderflow();
return true;
}
|
下溢修复
- 非根节点 v 下溢时,必恰有 ⌈m/2⌉−2 个关键码和 ⌈m/2⌉−1 个分支
- 若左兄弟 L 存在,且至少包含 ⌈m/2⌉ 个关键码(够借)
- 将 P 中分界关键码 y 移至 V 中(作为最小关键码)
- 将 L 中最大关键码 x 移至 P 中(取代 y)
- 修复完成
- 若右兄弟 R 存在,且至少包含 ⌈m/2⌉ 个关键码
- 若 L 和 R 或不存在,或均不足 ⌈m/2⌉ 个关键码
- 即便如此 L 和 R 必有其一,且恰含有 ⌈m/2⌉−1 个关键码
- 从 P 中抽出介于 L(R) 和 V 之间的关键码 y ,三者合成一个新的节点,同时合并此前 y 的孩子引用
- 这可能导致 P 继续下溢,重复整个过程即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| template<typename T> void BTree<T>::solveUnderflow(BTNodePosi<T> v) {
while ((_m + 1) / 2 > v->child.size()) {
BTNodePosi<T> p = v->parent;
if (!p) { }
Rank r = 0; while (p->child[r] != v) r++;
if (r > 0 && (_m + 1) / 2 < p->child[r - 1]->child.size()) {
} else if (r < p->child.size() - 1 && (_m + 1) / 2 < p->child[r + 1]->child.size()) {
} else {
if (r > 0) { }
else { }
}
v = p;
}
}
|
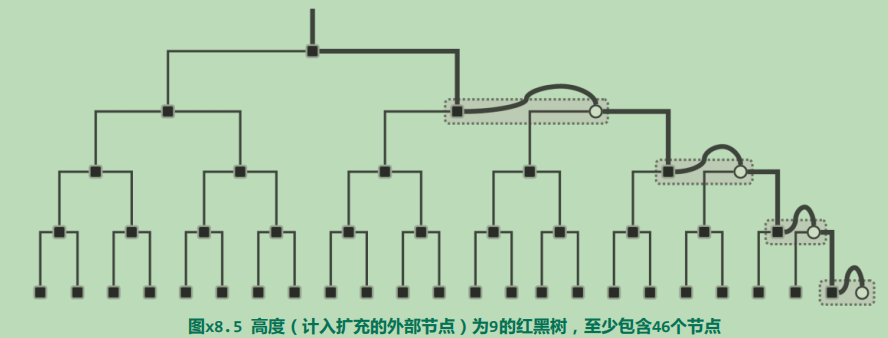
红黑树
动机
- 并发性:对于 BST 而言,结构变化处需要加锁(产生访问延迟)
- Splay 结构变化剧烈,最差 O(n)
- AVL 插入 O(1) 但删除 O(logn)
- 持久性:支持对历史版本的访问
- 蛮力保存,单次操作 O(logh+logn) ,累计 O(n⋅h) 时间/空间
- 压缩更新:大量共享,少量更新(仅支持对历史版本的读取)
- 每个版本的新增复杂度,仅为 O(logn)
- 可进一步提高至总体 O(n+h) 、单版本 O(1)
- 为此,就树的 代数结构 而言,相邻版本之间的差异不能超过 O(1)
结构
插入
- 按 BST 规则插入新关键码 e
- 除非是首个节点,否则 x 的父亲 p 必存在
- 先将 x 染红,条件 1、2、4 依然满足
- 但可能出现双红,此时考查
- 祖父
g = p->parent 必存在且为黑
- 叔父
u = uncle(x) = sibling(p) ,无非两种情况
1
2
3
4
5
6
7
8
| template<typename T> BinNodePosi<T> RedBlack<T>::insert(const T &e) {
BinNodePosi<T> &x = search(e);
if (x) return x;
x = new BinNode<T>(e, _hot, NULL, NULL, 0); _size++;
BinNodePosi<T> xOld = x;
solveDoubleRed(x); return xOld;
}
|
双红修正
RR-1: u->color = B
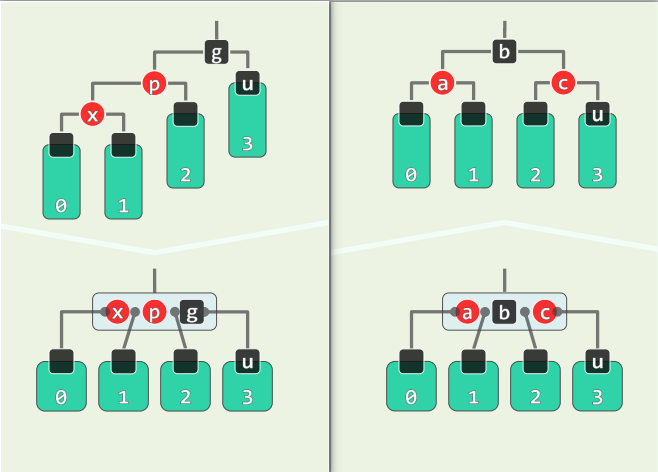
- 此时,x、p、g 的四个孩子(可能是外部节点)全黑,且黑高度相同
- 可进行局部“3+4”重构,b 转黑,a 或 c 转红
- 从 B-树的角度,相当于原三叉节点插入红关键码后,原黑关键码不再居中
RR-2: u->color = R
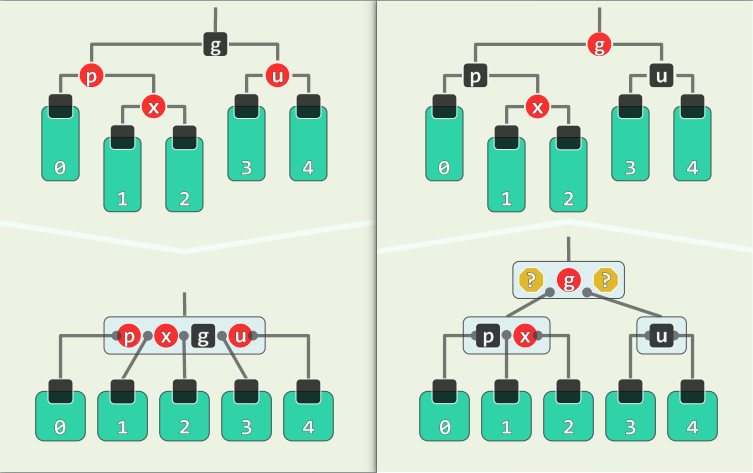
- 等效于在 B-树中,超级节点发生上溢
- 故可以让 p 和 u 转黑,g 转红
- 等效于 节点分裂,关键码 g 上升一层
- 所以可能将双红向上传播
- 继续如法炮制即可
- 直至不再双红,或抵达树根(整树黑高度+1)
复杂度
- 重构、染色均只需常数时间
- 故
RedBlack::insert() 仅需 O(logn) 时间
- 期间至多 O(logn) 次重染色、O(1) 次旋转
- 分摊意义下,重染色次数为 O(1)
|
旋转 |
染色 |
此后 |
| u 为黑 |
1~2 |
2 |
调整随即完成 |
| u 为红 |
0 |
3 |
可能再次双红,但必上升两层 |
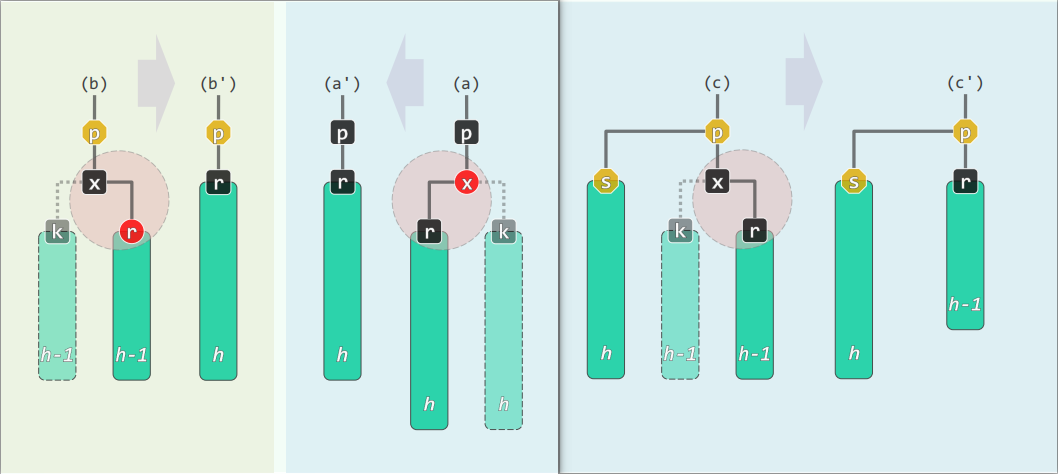
删除
- 首先按 BST 常规算法进行删除
r = removeAt(x, _hot)
- x 由其孩子 r 接替,此时另一孩子 k 必为 NULL
- 但实际调整过程中,x 可能逐层上升
- 故等效地理解为,k 是一棵 黑高度 与 r 相等的子树
-
此时条件 1、2 依然满足,但条件 3、4 未必
-
其一为红
- 若 x 为红,则 3、4 自然满足
- 若 r 为红,则令其与 x 交换颜色 即可
-
若 x 和 r 均黑,则此时全树黑深度不再统一
-
等效于 B-树中 x 所属节点发生下溢
-
在 新树 中,考查 r 的父亲,兄弟
1
2
| p = r->parent;
s = sibling(r);
|
无非四种情况,分别处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| template<typename T> bool RedBlack<T>::remove(const T &e) {
BinNodePosi<T> &x = search(e);
if (!x) return false;
BinNodePosi<T> r = removeAt(x, _hot);
if (!(--_size)) return true;
if (!_hot) {
_root->color = RB_BLACK; _root->updateHeight();
return true;
}
if (BlackHeightUpdated(_hot)) return true;
if (IsRed(r)) {
r->color = RB_BLACK;
r->height++; return true;
}
solveDoubleBlack(r); return true;
}
|
双黑修正
BB-1
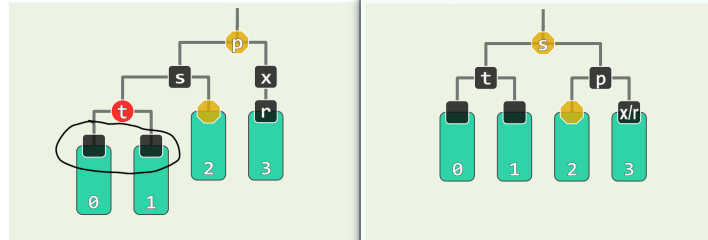
- s 为黑,且至少有一个红孩子 t
- 进行“3+4”重构,r 保持黑,a、c 染黑,b 继承 p 的原色
BB-2R
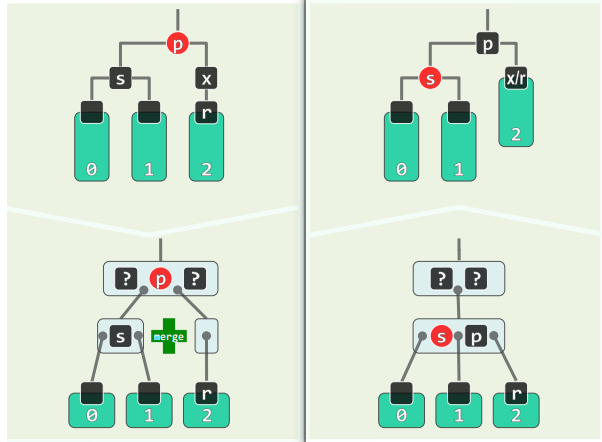
- s 为黑,且两个孩子均为黑;p 为红
- r 保持黑,s 转红,p 转黑
- 等效于下溢节点与兄弟节点合并
- 同时因为 p 左右还有黑关键码,不会导致下溢传播
BB-2B
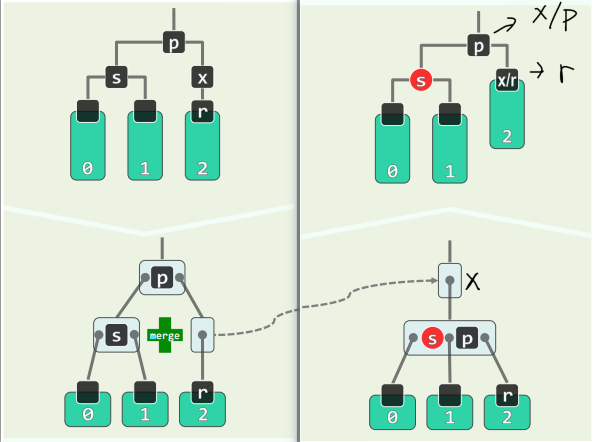
- s 为黑,且两个孩子均为黑;p 为黑
- r 保持黑,s 转红,p 转黑
- 也等效于下溢节点与兄弟节点合并
- 但合并前,p 和 s 均属于单关键码节点,故 父节点继续下溢
- 继续处理即可,至多 O(logn) 步
BB-3
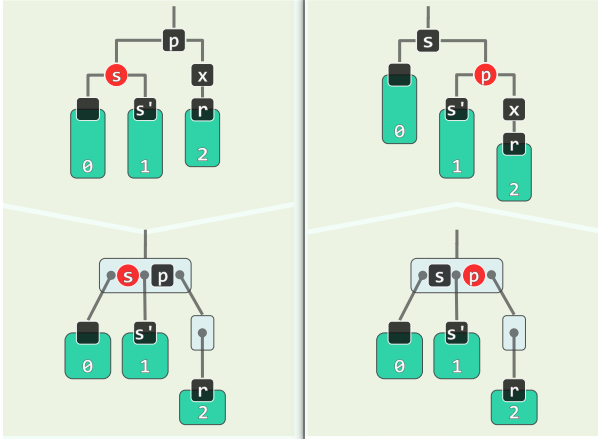
- s 为红(其孩子均为黑)
- 绕 p 单旋,s 由红转黑,p 由黑转红
- 黑高度依然异常,但 r 有了新的(黑)兄弟
- 且由于 p 转红,接下来的情况变为 BB-1 或 BB-2R
- 再调整一轮,即可恢复
- 道理是“存在红色就可以在子树中腾挪”,但需要先调整一下形态
- 想在红黑树的等效 B-树节点中交换节点颜色(即在 B-树中改变与上层节点的联接),需要进行旋转
复杂度
RedBlack<T>::remove 仅需 O(logn) 时间
- 期间至多 O(logn) 次重染色、O(1) 次旋转
- 分摊意义下,重染色次数为 O(1)
|
旋转 |
染色 |
此后 |
| (1)黑 s 有红子 t |
1~2 |
3 |
调整随即完成 |
| (2R)黑 s 无红子,p 红 |
0 |
2 |
调整随即完成 |
| (2B)黑 s 无红子,p 黑 |
0 |
1 |
必再次双黑,但上升一层 |
| (3)红 s |
1 |
2 |
转为(1)或(2R) |